Aprendizaje Automático sobre
Grandes Volúmenes de Datos
Clase 13
Pablo Ariel Duboue, PhD
Universidad Nacional de Córdoba,
Facultad de Matemática, Astronomía y Física

None.1 Décima Tercera Clase: Métodos Alternativos
None.1.1 Clase anterior
Material de lectura
-
Clase pasada:
-
Scalable Scientific Computing Algorithms Using MapReduce por Xiang Jingen, Master of Mathematics UWaterloo ’13
- https://uwspace.uwaterloo.ca/bitstream/handle/10012/7830/Xiang_Jingen.pdf
- Parallelized stochastic gradient descent por Zinkevich, Weimer, Li, Smola (NIPS 2010)
-
Scalable Scientific Computing Algorithms Using MapReduce por Xiang Jingen, Master of Mathematics UWaterloo ’13
-
Ésta clase:
-
Alternating Direction Method of Multipliers (Boyd et al. 2011)
- web.stanford.edu/~boyd/papers/pdf/admm_distr_stats.pdf
-
MPI (http://en.wikipedia.org/wiki/Message_Passing_Interface)
- http://www.mpich.org/
-
Colas de pasaje de mensajes (http://en.wikipedia.org/wiki/Advanced_Message_Queuing_Protocol)
- http://activemq.apache.org/
-
Alternating Direction Method of Multipliers (Boyd et al. 2011)
Preguntas
- ¡Sin preguntas!
Recordatorio
-
El sitio Web de la materia es http://aprendizajengrande.net
- Allí está el material del curso (filminas, audio)
-
Leer la cuenta de Twitter https://twitter.com/aprendengrande es obligatorio antes de venir a clase
- Allí encontrarán anuncios como cambios de aula, etc
- No necesitan tener cuenta de Twitter para ver los anuncios, simplemente visiten la página
-
Suscribirse a la lista de mail en aprendizajengrande@librelist.com es optativo
- Si están suscriptos a la lista no necesitan ver Twitter
-
Feedback para alumnos de posgrado es obligatorio y firmado, incluyan si son alumnos de grado, posgrado u oyentes
- El "resúmen" de la clase puede ser tan sencillo como un listado del título de los temas tratados
None.2 Clase Anterior
Temas Claves
- Identificación de la máxima tarea que puede hacerse por nodo
- Descomposición de la tarea normal en tareas por nodo
- Tareas globales, realizadas en un nodo (central) y tareas paralelas
- Comunicación entre tareas mediante HDFS y archivos bandera
- Tareas que sólo hacen Map
- Cálculos intermedios
Descomposición LU
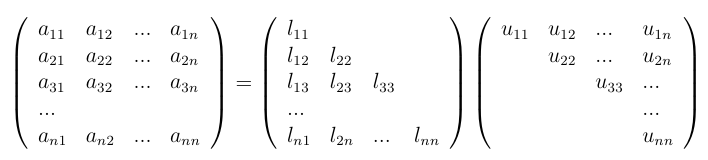
(adaptado de Xiang Jingen, 2013)
Descomposición LU en MR
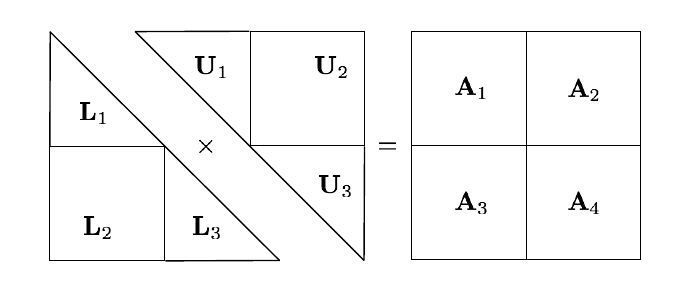
(adaptado de Xiang Jingen, 2013)
Descomposición LU en MR
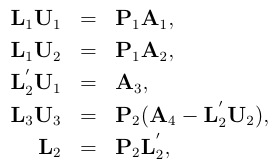
(adaptado de Xiang Jingen, 2013)
El algoritmo a vuelo de pájaro
- Dividir la matriz original recursivamente hasta que L1 U1 = P1 A1 sea soluble en una máquina
- Descomponer A1
- Calcular U2
- Calcular la permutación de L2, L’2
- Calcular B = A4 − L’2 U2
- Descomponer B
- Armar la salida total a partir las partes
Implementación en MapReduce
-
Nodo master crea archivos de control que son usados como entrada a las tareas map subsecuentes
- Falsas entradas
- Una tarea MapReduce subdivide A de manera recursiva
-
Se envian tareas MapReduce para L’2, U2 y B
- L1 y U1 son ejecutadas en el master node si A1es lo suficientemente pequeña
Número de Tareas
- m0 es la cantidad de máquinas en el cluster
- nb es el máximo tamaño de una matriz para computar en un solo nodo
- Número de tareas será 2⌈log2(n)/(nb)⌉:

(adaptado de Xiang Jingen, 2013)
Ejecución
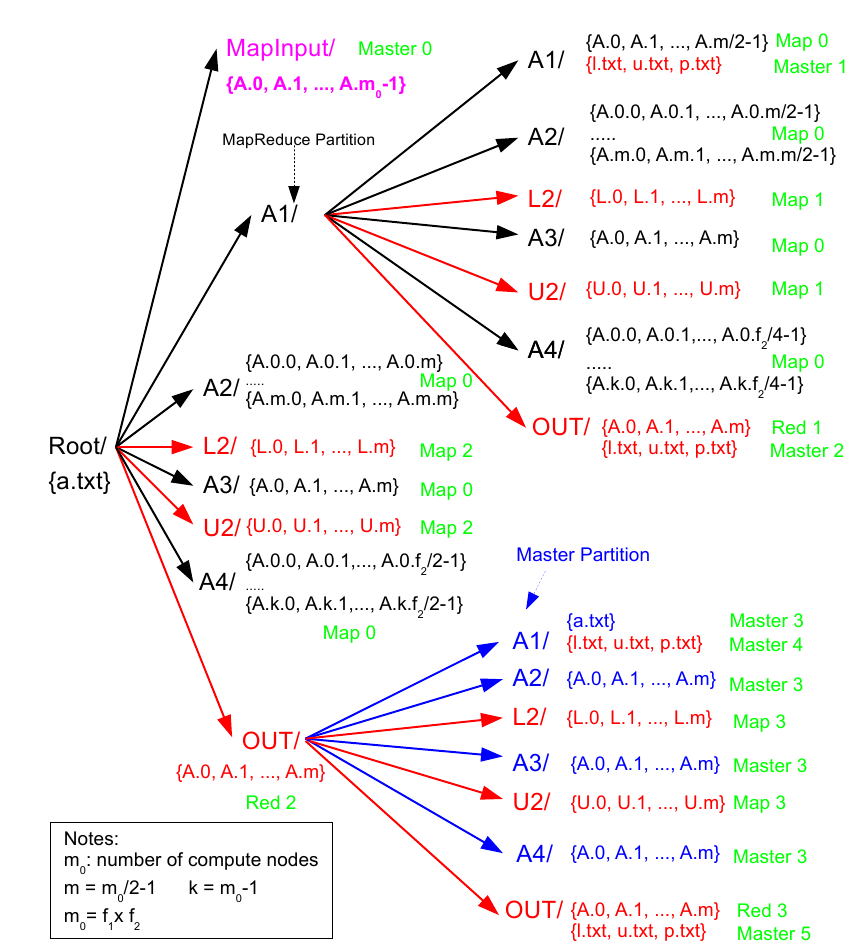
(adaptado de Xiang Jingen, 2013)
None.3 Descenso por el gradiente distribuido
Zinkevich et al., NIPS 2010
- Distribuir los datos al azar entre nodos
- Realizar descenso por el gradiente en cada nodo, por separado
- Unificar los resultados en un nodo central
Algoritmo en nodo worker

(adaptado de Zinkevich et al, 2010)
Algoritmo en nodo central

(adaptado de Zinkevich et al, 2010)
None.4 Método de Dirección Alternada de Multiplicadores
Dirección Alternada de Multiplicadores
-
Optimizar dos funciones a la vez
- Problema similar a regresión logística y SVMs
- Alternar la optimización de una función y la otra
- Clave: en ciertas condiciones, la primera optimización se puede hacer en paralelo mientras que la segunda es reducida y puede hacerse en una sola máquina
minimizar
f(x) + g(z)
dado que
Ax + Bz = c
- Ver Distributed Optimization and Statistical Learning via the Alternating Direction Method of Multipliers (201) por Boyd, Parikh, Chu, Peleato, Eckstein
None.5 Métodos Alternativos
-
Más allá de MapReduce:
- MPi: Message Passing Interface
- AMQP: Advanced Message Queuing Protocol
MPI
-
Estándar de facto
- Desde 1994
- Tres revisiones
-
Especificaciones independientes del lenguaje para llamadas de función
- CORBA o RPC
- Mucha menor latencia entre llamadas
- Mismo programa en todos los nodos, se pasan datos entre ellos
MPI
-
Provee:
- Topología virtual
- Sincronización
- Comunicación
-
Funciones:
- Comunicación punto-a-punto (rendez-vous), send/receive
- Topología Cartesiana o de grafo general
- Combinar resultados parciales (gather/reduce)
- Sincronización de nodos (barreras)
- Información general (número de nodos, número de nodo actual, vecinos, topología)
Decisiones de diseño
- Todo el paralelismo es explícito
- Distintas implementaciones (en distinto hardware) sólo requieren recompilación del código
Implementación de ejemplo: MPICH
- Programas mpicc y mpiexec
- ssh con certificados (sin password)
-
mpiexec -f lista-de-hostnames -n <número> programa-ejecutable
- La lista de hostnames puede tener de manera opcional el número de cores después de un :
- mpiexec -f lista-de-hostnames -n 1 ./master : -n 15 ./slave
-
Diferentes métodos de comunicación entre procesos
- Más recient "némesis" usa memoria compartida para procesos en la misma máquina y sockets (o Myrinet-MX) para comunicación entre red
Ejemplo
#include <mpi.h>
#include <stdio.h>
int main(int argc, char ** argv) {
#include <stdio.h>
int main(int argc, char ** argv) {
int rank, size;
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &size);
printf("I am %d of %d\n", rank + 1, size);
MPI_Finalize();
return 0;
}
}
Adapted from http://www.mcs.anl.gov/~balaji/permalinks/2014-06-06-argonne-mpi-basic.pptx
Diferencia con MapReduce
-
MapReduce es un subconjunto del estándar MPI
- Operaciones collectivas y operaciones de usuario
- MPI no es tolerante a fallas
-
MPI provee muchas más primitivas
- Requiere que el programador se ocupe de muchos más detalles
-
En el caso de inversión de matrices, la implementación MPI es más eficiente para matrices pequeñas pero tiene mucho mayor overhead de comunicación
- Escala de manera más pobre
Message Queues
-
Message-Oriented Middleware (MOM)
- Soporte por software o hardware
- Envío y recepción de mensajes
- Redes distribuidas heterogéneas
-
Normalmente asíncrono
- Colas
- Potencialmente persistentes (tolerancia a fallos)
- Ruteo
- Potencial transformación
-
Requiere un message transfer
- Talón de Aquiles
Advanced Message Queuing Protocol (AMQP)
- Estándar OASIS
-
Características:
- Orientación de mensajes
- Colas
-
Ruteo
- Punto-a-punto
- Publish-and-subscribe
- Confiabilidad
- Seguridad
- Protocolo a nivel del cable: información en formato de octetos (protocolo binario)
Especificación AMQP
-
Sistema de tipos
- Tipos primitivos
- Diccionarios
- Protocolo simétrico, asíncrono para enviar mensajes
- Un formato de mensajes estándar y extensible
- Un conjunto estándar pero extensible de "capacidades de mensajería"
-
Semánticas de recepción:
- at-most-once
- at-least-once
- exactly-once
ActiveMQ
- Proyecto de la fundación Apache
- Java
-
Ejecutar el broker:
- bin/activemq
-
Ejecutar programas clientes pasandole información sobre el host/puerto del broker
- Normalmente vía variables de entorno
Ejemplo
String user = env("ACTIVEMQ_USER", "admin");
String password = env("ACTIVEMQ_PASSWORD", "password");
String host = env("ACTIVEMQ_HOST", "localhost");
int port = Integer.parseInt(env("ACTIVEMQ_PORT", "61616"));
String destination = arg(args, 0, "event");
ActiveMQConnectionFactory factory = new ActiveMQConnectionFactory("tcp://" + host + ":" + port);
Connection connection = factory.createConnection(user, password);
connection.start(); Session session = connection.createSession(false, Session.AUTO_ACKNOWLEDGE);
Destination dest = new ActiveMQTopic(destination);
MessageProducer producer = session.createProducer(dest);
producer.setDeliveryMode(DeliveryMode.NON_PERSISTENT);
TextMessage msg = session.createTextMessage(body);
msg.setIntProperty("id", 1); producer.send(msg);
producer.send(session.createTextMessage("SHUTDOWN")); connection.close();
AMQP vs. MapReduce
- El broker es el eslabón más débil
-
Topología explícita en AMQP
- Más versátil
- Más trabajo por parte del programador
-
Tolerancia a fallas de AMQP es potencialmente mejor que MapReduce
- Cómputos intermedios pueden ser mantenidos en colas persistentes