Aprendizaje Automático sobre
Grandes Volúmenes de Datos
Clase 14
Pablo Ariel Duboue, PhD
Universidad Nacional de Córdoba,
Facultad de Matemática, Astronomía y Física

None.1 Décima Cuarta Clase: Paralelizando Naive Bayes
None.1.1 Clase anterior
Material de lectura
-
Clase pasada:
-
Alternating Direction Method of Multipliers (Boyd et al. 2011)
- web.stanford.edu/~boyd/papers/pdf/admm_distr_stats.pdf
-
MPI (http://en.wikipedia.org/wiki/Message_Passing_Interface)
- http://www.mpich.org/
-
Colas de pasaje de mensajes (http://en.wikipedia.org/wiki/Advanced_Message_Queuing_Protocol)
- http://activemq.apache.org/
-
Alternating Direction Method of Multipliers (Boyd et al. 2011)
-
Ésta clase:
-
Tackling the Poor Assumptions of Naive Bayes Text Classifiers
- Rennie et al., ICML 2003
- http://people.csail.mit.edu/jrennie/papers/icml03-nb.pdf
- http://www.cs.columbia.edu/~smaskey/CS6998-0412/slides/week7_statnlp_web.pdf
- http://spectrallyclustered.wordpress.com/2013/02/20/naive-bayes-on-hadoop/
- http://machinomics.blogspot.com.ar/2013/11/naive-bayes-with-map-reduce.html
-
Tackling the Poor Assumptions of Naive Bayes Text Classifiers
Preguntas
-
¿Cuándo usar MR vs. MPI vs. AMQ?
- MR: programadores sin experiencia en cálculo distribuido, hardware barato
- MPI: hardware dedicado de buena calidad
- AMQ: programadores con experiencia en cálculo distribuido, hardware con acceso restringido a Internet
-
¿Cómo calcular la tarea máxima?
- Depende de la tarea y las máquinas
-
¿MPI con DFS?
- Es posible, pero no dá el caso de uso
-
Distribución de datos en descenso por el gradiente, ¿se realiza al comienzo?
- Sí, y por eso se puede usar una implementación de descenso por el gradiente ya conocida
Recordatorio
-
El sitio Web de la materia es http://aprendizajengrande.net
- Allí está el material del curso (filminas, audio)
-
Leer la cuenta de Twitter https://twitter.com/aprendengrande es obligatorio antes de venir a clase
- Allí encontrarán anuncios como cambios de aula, etc
- No necesitan tener cuenta de Twitter para ver los anuncios, simplemente visiten la página
-
Suscribirse a la lista de mail en aprendizajengrande@librelist.com es optativo
- Si están suscriptos a la lista no necesitan ver Twitter
-
Feedback para alumnos de posgrado es obligatorio y firmado, incluyan si son alumnos de grado, posgrado u oyentes
- El "resúmen" de la clase puede ser tan sencillo como un listado del título de los temas tratados
None.2 Clase Anterior
Filmínas de la defensa de Jingen Xiang
- Filmínas 28-36
Zinkevich et al., NIPS 2010
- Distribuir los datos al azar entre nodos
- Realizar descenso por el gradiente en cada nodo, por separado
- Unificar los resultados en un nodo central
Algoritmo en nodo worker

(adaptado de Zinkevich et al, 2010)
Algoritmo en nodo central

(adaptado de Zinkevich et al, 2010)
Dirección Alternada de Multiplicadores
-
Optimizar dos funciones a la vez
- Problema similar a regresión logística y SVMs
- Alternar la optimización de una función y la otra
- Clave: en ciertas condiciones, la primera optimización se puede hacer en paralelo mientras que la segunda es reducida y puede hacerse en una sola máquina
minimizar
f(x) + g(z)
dado que
Ax + Bz = c
- Ver Distributed Optimization and Statistical Learning via the Alternating Direction Method of Multipliers (201) por Boyd, Parikh, Chu, Peleato, Eckstein
MPI
-
Estándar de facto
- Desde 1994
- Mismo programa en todos los nodos, se pasan datos entre ellos
-
Provee:
- Topología virtual, Sincronización, Comunicación
-
Funciones:
- Comunicación punto-a-punto (rendez-vous), send/receive
- Topología Cartesiana o de grafo general
- Combinar resultados parciales (gather/reduce)
- Sincronización de nodos (barreras)
- Información general (número de nodos, número de nodo actual, vecinos, topología)
MPI vs. MapReduce
-
MapReduce es un subconjunto del estándar MPI
- Operaciones collectivas y operaciones de usuario
- MPI no es tolerante a fallas
-
MPI provee muchas más primitivas
- Requiere que el programador se ocupe de muchos más detalles
-
En el caso de inversión de matrices, la implementación MPI es más eficiente para matrices pequeñas pero tiene mucho mayor overhead de comunicación
- Escala de manera más pobre
Message Queues
-
Message-Oriented Middleware (MOM)
- Soporte por software o hardware
- Envío y recepción de mensajes
- Redes distribuidas heterogéneas
-
Normalmente asíncrono
- Colas
- Potencialmente persistentes (tolerancia a fallos)
- Ruteo
- Potencial transformación
-
Requiere un message transfer
- Talón de Aquiles
AMQP vs. MapReduce
- El broker es el eslabón más débil
-
Topología explícita en AMQP
- Más versátil
- Más trabajo por parte del programador
-
Tolerancia a fallas de AMQP es potencialmente mejor que MapReduce
- Cómputos intermedios pueden ser mantenidos en colas persistentes
None.3 Paralelizando Naive Bayes
Naive Bayes
- Teorema de Bayes
P(y|f⃗) = (P(f⃗|y)P(y))/(P(f⃗))
- Naive Bayes asume que las features son probabilisticamente independientes
yNB = maxyP(f1, ..., fn|y)P(y) = maxyP(f1|y)...P(fn|y)P(y)
- Podemos estimar P(fi|y) a partir de conteos
NB: de conteos a probabilidades
- Conteos de instancias (Ni) vs. conteos de features (Nf)
-
De la definición de probabilidad conjunta:P(".com"|Arts)P(Arts) = P(".com", Arts) = (Nf(".com", Arts))/(Nf(.))
-
De la definición de probabilidad simple:P(Arts) = (Ni(Arts))/(Ni(.))
-
Despejando para la probabilidad condicional:P(".com"|Arts) = (Ni(.))/(Nf(.))(Nf(".com", Arts))/(Ni(Arts))
Ejemplo: Contar Palabras
-
map(input_key: DocName, input_value: DocText):
-
for each word w in input_value:
- EmitIntermediate(w, 1)
-
for each word w in input_value:
-
reduce(output_key: Word, intermediate_values: List[Int]):
- int result = 0
-
for each v in intermediate_values:
- result += v
- Emit(result)
Naive Bayes en MapReduce
-
map(clave={features con nombres y valores}, valor: función objetivo)
- devuelve clave=función objetivo:nombre del features, valor=valor del feature
-
reduce(clave=función objetivo y0:nombre del feature Fi, valor=valor del feature vi, 0):
-
calcular P(Fi = vi, 0|y = y0):
- Calcular la suma sobre todos los valores posibles para el feature dado y usarla para normalizar
- devuelve clave=función objetivo:nombre del feature, valor=valor del feature:probabilidad
-
calcular P(Fi = vi, 0|y = y0):
En python
- https://github.com/analyticbastard/myml/blob/master/myml/supervised/bayes.py
-
def map(self, key, value):
-
for i, k in enumerate(key):
- yield (value, i), k
-
for i, k in enumerate(key):
-
def reduce(self, key, values):
- val = set(values)
- N = len(values)
-
for newkey in val:
- yield (key[0], key[1], newkey), 1.0*np.sum(values == newkey)/N
Implementación Alternativa
-
Necesitamos calcular:
- #(Y=*): número total de instancias (documentos)
- #(Y=y): número de instancias por valor de la función objetivo (etiqueta)
- #(Y=y,F=*): número de valores de features (palabras) para un cierto valor de la función objetivo (etiqueta)
- #(Y=y,F=v): numero veces un cierto valor de una cierta feature (palabra) aparece bajo un cierto valor de la función objetivo (etiqueta)
- dom(X): cuántos valores posibles pueden tomar las features (vocabulario)
- dom(Y): cuántos valores puede tomar la función objetivo (etiquetas)
Calculando valores independientes de las instancias
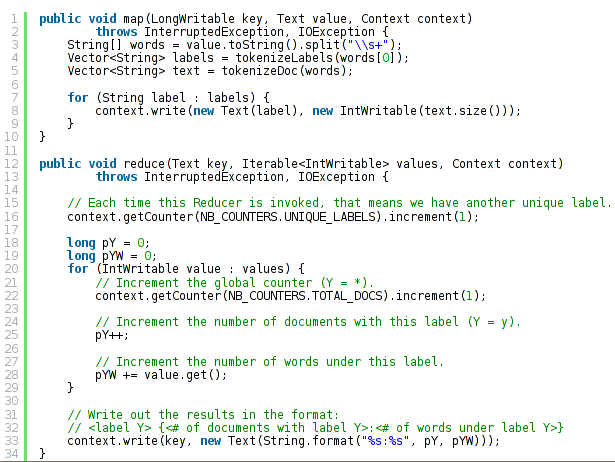
(Adaptado de http://spectrallyclustered.wordpress.com/2013/02/20/naive-bayes-on-hadoop/)
Calculando valores dependientes de las instancias
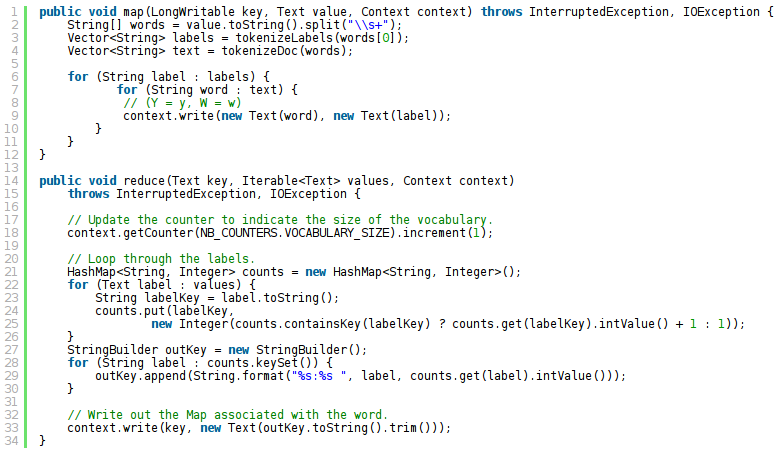
(Adaptado de http://spectrallyclustered.wordpress.com/2013/02/20/naive-bayes-on-hadoop/)
Corrigiendo los errores de Naive Bayes
-
Tackling the Poor Assumptions of Naive Bayes Text Classifiers
- Rennie et al., ICML 2003
-
Naive Bayes tiene problemas con:
- Clases desbalanceadas
- Mayoría de datos dependientes en una clase vs. en otra
- Distribuciones específicas a datos textuales
Algoritmo mejorado

(Adaptado de Rennie et al., 2003)