Aprendizaje Automático sobre
Grandes Volúmenes de Datos
Clase 9
Pablo Ariel Duboue, PhD
Universidad Nacional de Córdoba,
Facultad de Matemática, Astronomía y Física

None.1 Novena Clase: Map Reduce
None.1.1 Clase anterior
Material de lectura
-
Clase pasada:
- Capítulo 2 y 4 del Owen et al. (2012)
-
Ésta clase:
-
MapReduce: Simplified Data Processing on Large Clusters by Jeffrey Dean and Sanjay Ghemawat
- OSDI’04: Sixth Symposium on Operating System Design and Implementation, San Francisco, CA, December, 2004
-
The Google File System by Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung
- 19th ACM Symposium on Operating Systems Principles, Lake George, NY, October, 2003.
-
MapReduce: Simplified Data Processing on Large Clusters by Jeffrey Dean and Sanjay Ghemawat
Preguntas
-
k-Means y features de tipo enumeración
- ¿Cómo definir el centroide para features categoriales (e.g., "frío, calor, templado")?
-
En ese caso el centroide no necesita tener la misma representación que los elementos normales
- Distribución de probabilidad sobre cada categoría
- Hay dos funciones de distancia: distancia entre instancias y distancia entre instancia y centroide
-
Evaluación de sistemas de recomendación
- Evaluar sistemas de recomendación es todavía un problema abierto
-
Se utilizan técnicas donde se mantiene un porcentaje de preferencias oculto y después se usa Precision/Recall para evaluar
- Técnica "injusta" y depende de cada partición
Recordatorio
-
El sitio Web de la materia es http://aprendizajengrande.net
- Allí está el material del curso (filminas, audio)
-
Leer la cuenta de Twitter https://twitter.com/aprendengrande es obligatorio antes de venir a clase
- Allí encontrarán anuncios como cambios de aula, etc
- No necesitan tener cuenta de Twitter para ver los anuncios, simplemente visiten la página
-
Suscribirse a la lista de mail en aprendizajengrande@librelist.com es optativo
- Si están suscriptos a la lista no necesitan ver Twitter
-
Feedback para alumnos de posgrado es obligatorio y firmado, incluyan si son alumnos de grado, posgrado u oyentes
- El "resúmen" de la clase puede ser tan sencillo como un listado del título de los temas tratados
None.1.2 Cómputo Distribuido
Cómputo Distribuido
- MapReduce
- Teorema CAP
- Operaciones Matriciales Distribuidas
- Descenso por el Gradiente (Búsqueda distribuida)
- Algoritmos actualizables, Colas, shared memory
- Paralelizando Algoritmos de Aprendizaje Automático
Modelo de Cluster de Máquinas
-
Máquinas autónomas con espacio de disco local
- Sin memoria compartida
-
Con una topología de red jerárquica
- Máquinas en un mismo switch
- Máquinas en un mismo rack
-
Máquinas de poca confiabilidad
- Fallas en el sistema son algo no solo probable si no esperable
MapReduce
- Modelo de cómputo que simplifica el uso de clusters
-
Computa una función f({(kin, vin)}) → {(kout, list(vout)}
- map(kin, vin) → list(kout, vint)
- reduce(kout, list(vint)) → list(vout)
Teorema CAP
-
Cuando estamos en un ambiente distribuido, de estas tres características sólo podes escoger dos:
- Consistencia
- Disponibilidad
- Tolerancia a particiones de la red
Operaciones Matriciales Distribuidas
- Distribución de matrices a nodos
- Matriz por Vector
- (Matriz por Matriz)
- (Inversión Matricial)
Descenso por el Gradiente
-
Descenso por el Gradiente
- Parallelized stochastic gradient descent por M Zinkevich, M Weimer, L Li, AJ Smola en NIPS 2010
-
Búsqueda distribuida
- (Algoritmos genéticos)
Otros Modelos
- Sistemas por Colas
- Memoria Compartida
Paralelizando Algoritmos
-
Algoritmos Actualizables
- Naive Bayes
- Random Forests
- (Regresión Logística)
None.1.3 Map/Reduce
Objetivo
- Simplificar el acceso al cómputo de gran volúmen de datos para programadores sin experiencia en cómputo distribuido
- Simplificar la tolerancia a fallas
- Simplificar la alocación de recursos (máquinas, disco y red)
Modelo de Programación
-
Computa una función f({(kin, vin)}) → {(kout, list(vout)}
-
map(kin, vin) → list(kout, vint)
- Para cada par (clave, valor) de entrada, produce una lista de pares de otros claves y valores intermedios
-
reduce(kout, list(vint)) → list(vout)
- Acumular los valores intermedios según su clave de salida
- Generar la salida combinada
-
map(kin, vin) → list(kout, vint)
Ejemplo: Contar Palabras
-
map(input_key: DocName, input_value: DocText):
-
for each word w in input_value:
- EmitIntermediate(w, 1)
-
for each word w in input_value:
-
reduce(output_key: Word, intermediate_values: List[Int]):
- int result = 0
-
for each v in intermediate_values:
- result += v
- Emit(result)
Ejemplos de Uso en Google
- distributed grep
- distributed sort
- web link-graph reversal
- term-vector per host
- web access log stats
- inverted index construction
- document clustering
- machine learning
- statistical machine translation
Ejecución
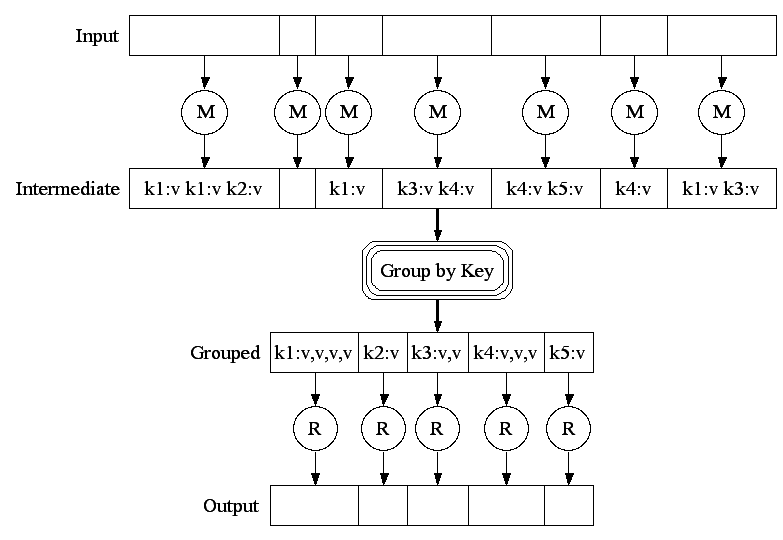
(fuente: http://research.google.com/archive/mapreduce-osdi04-slides/index-auto-0007.html)
En Paralelo
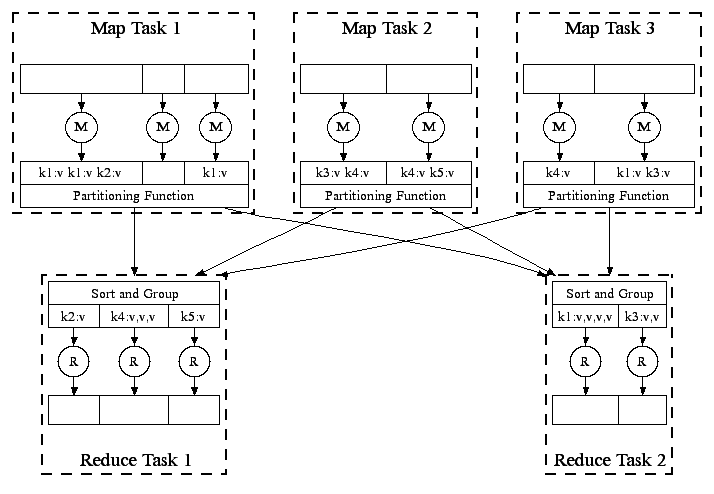
(fuente: http://research.google.com/archive/mapreduce-osdi04-slides/index-auto-0008.html)
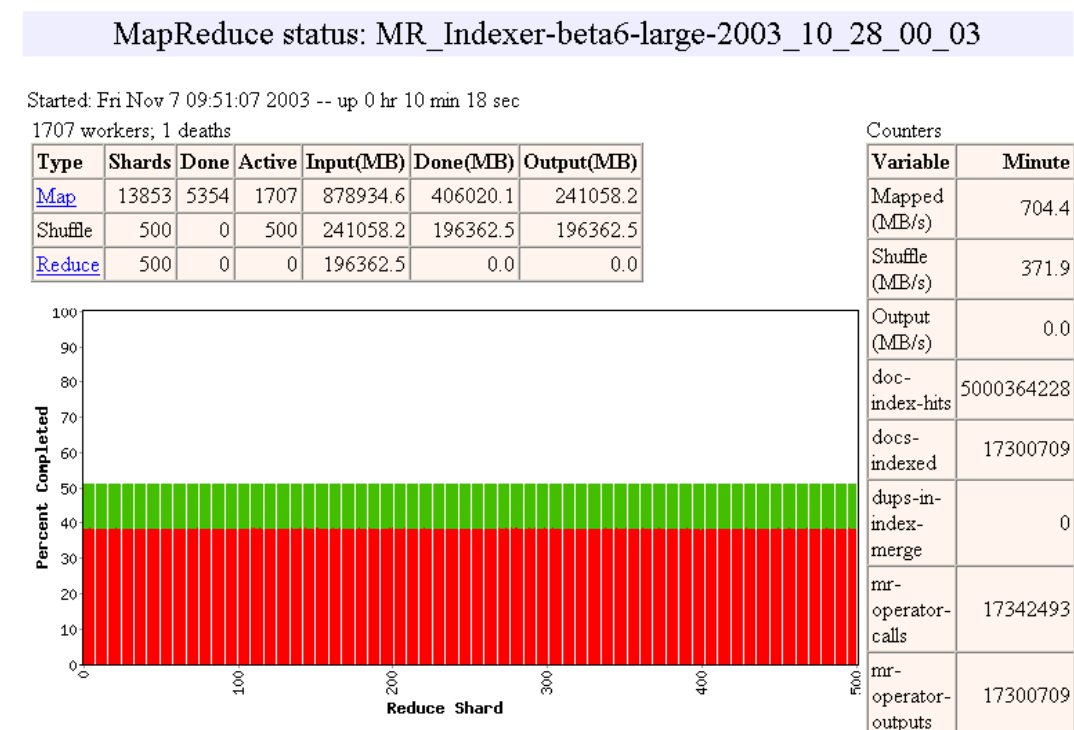
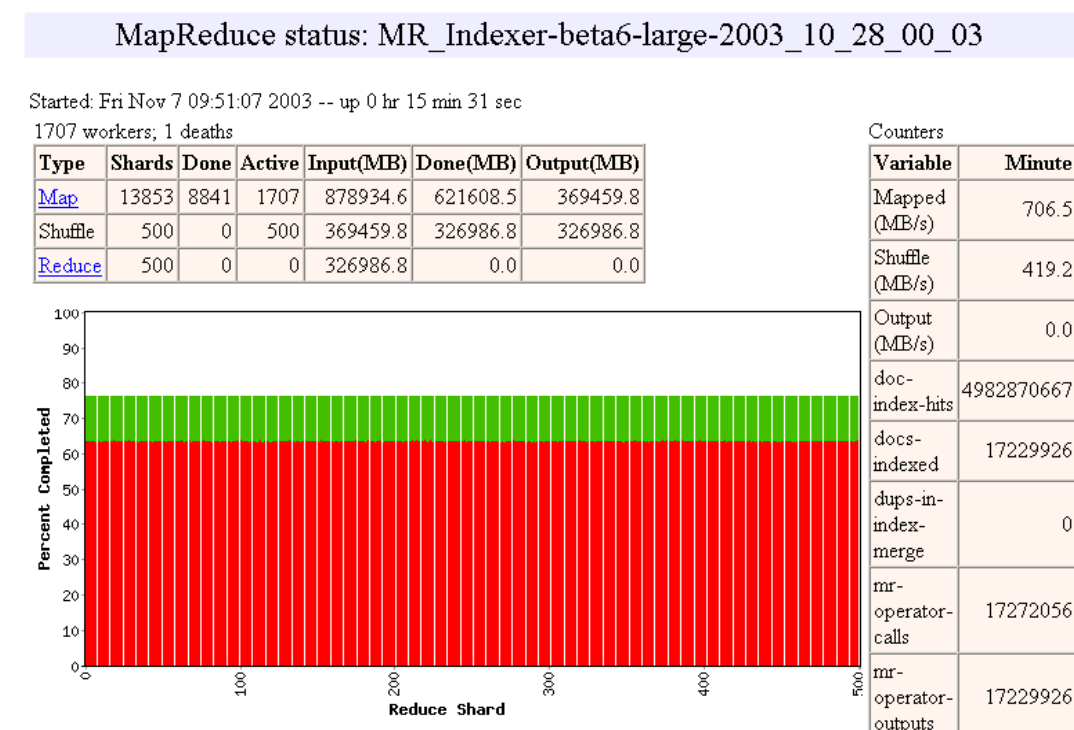
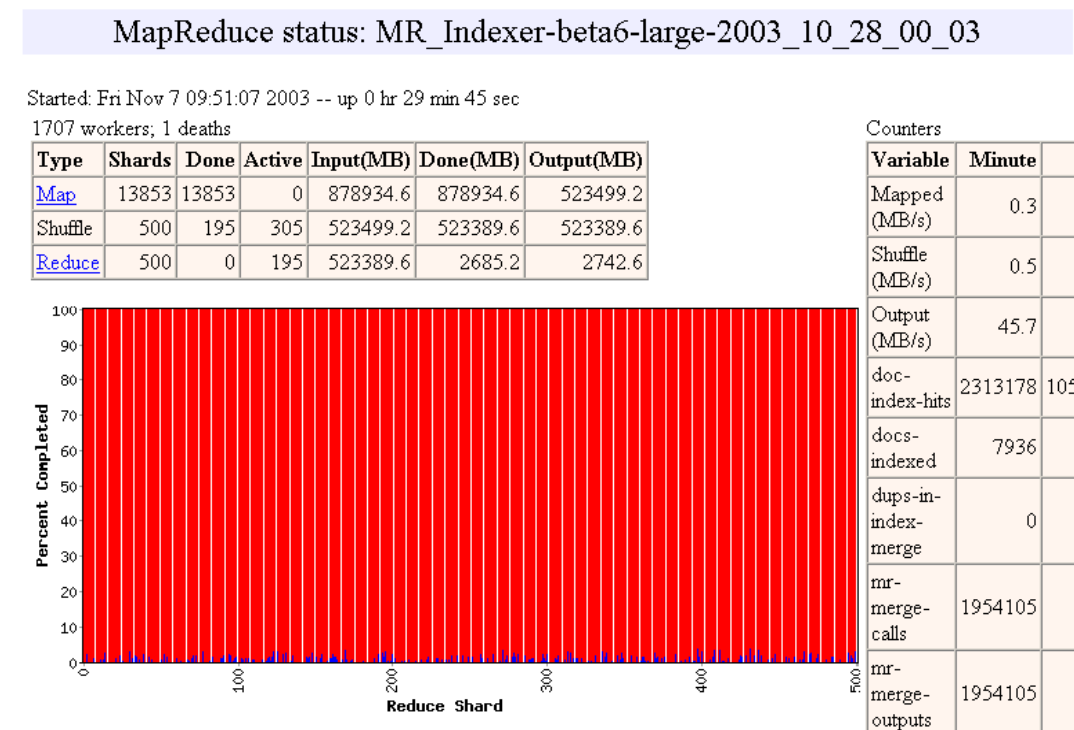
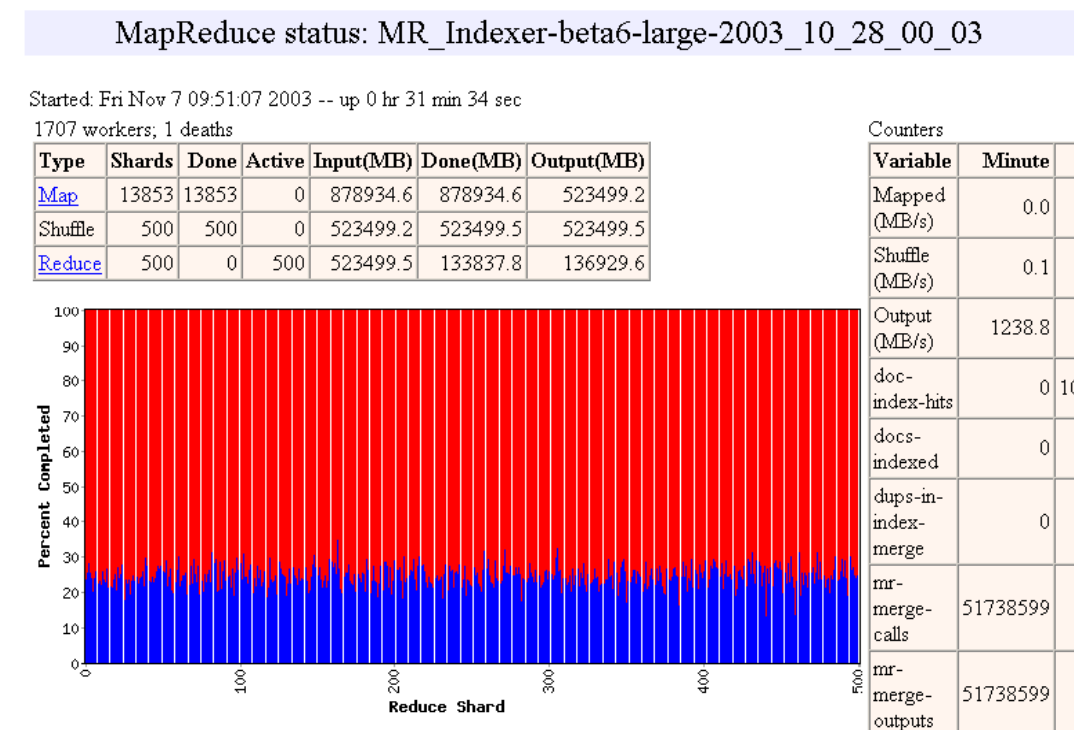
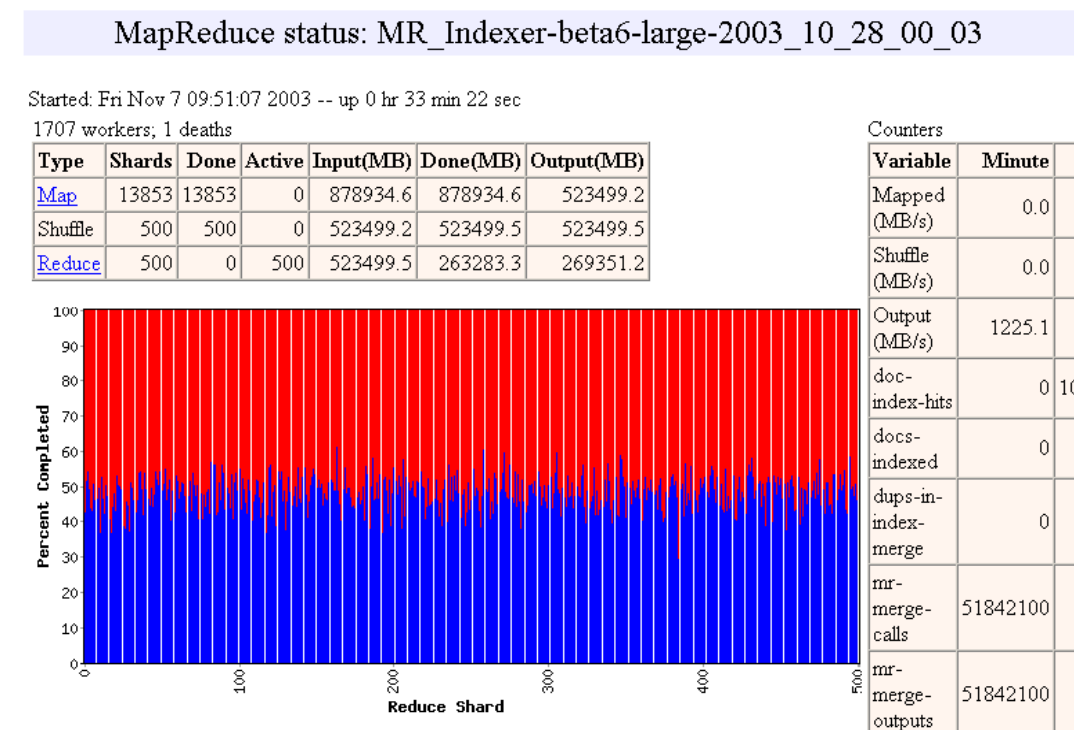
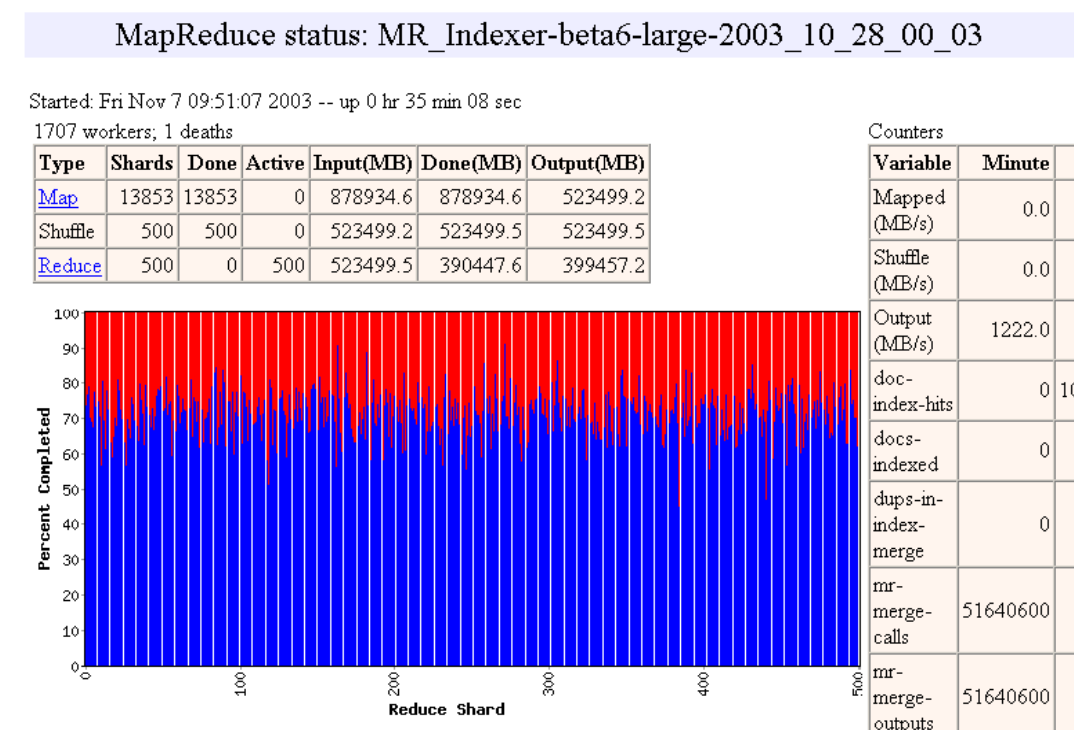
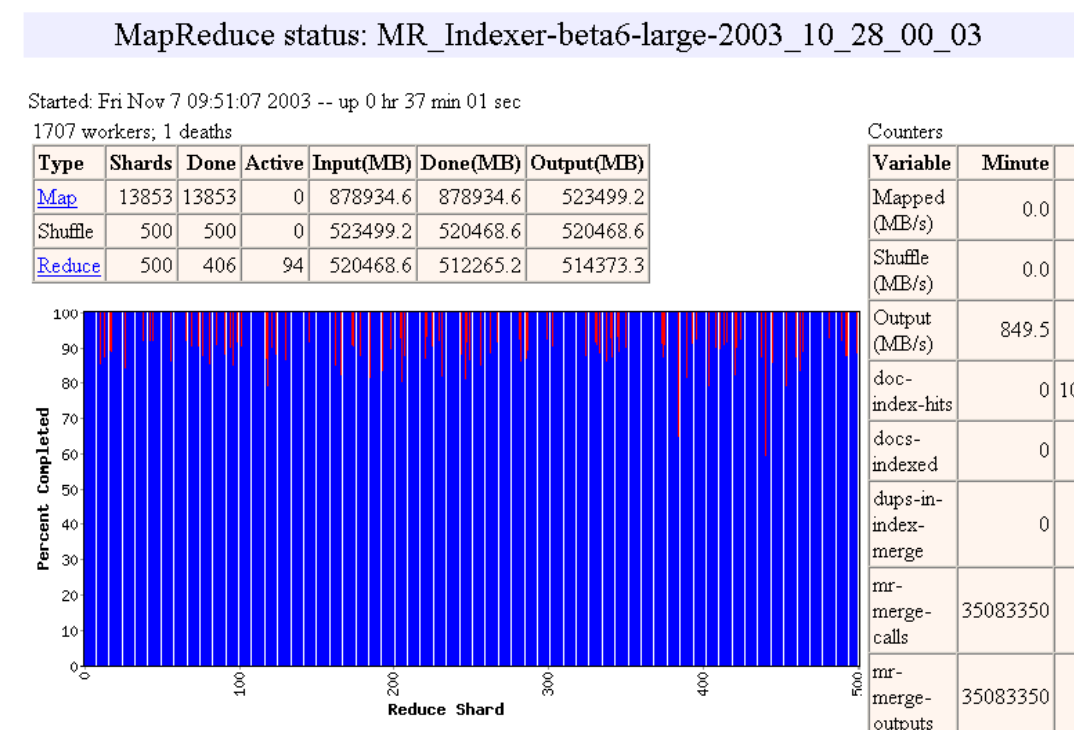
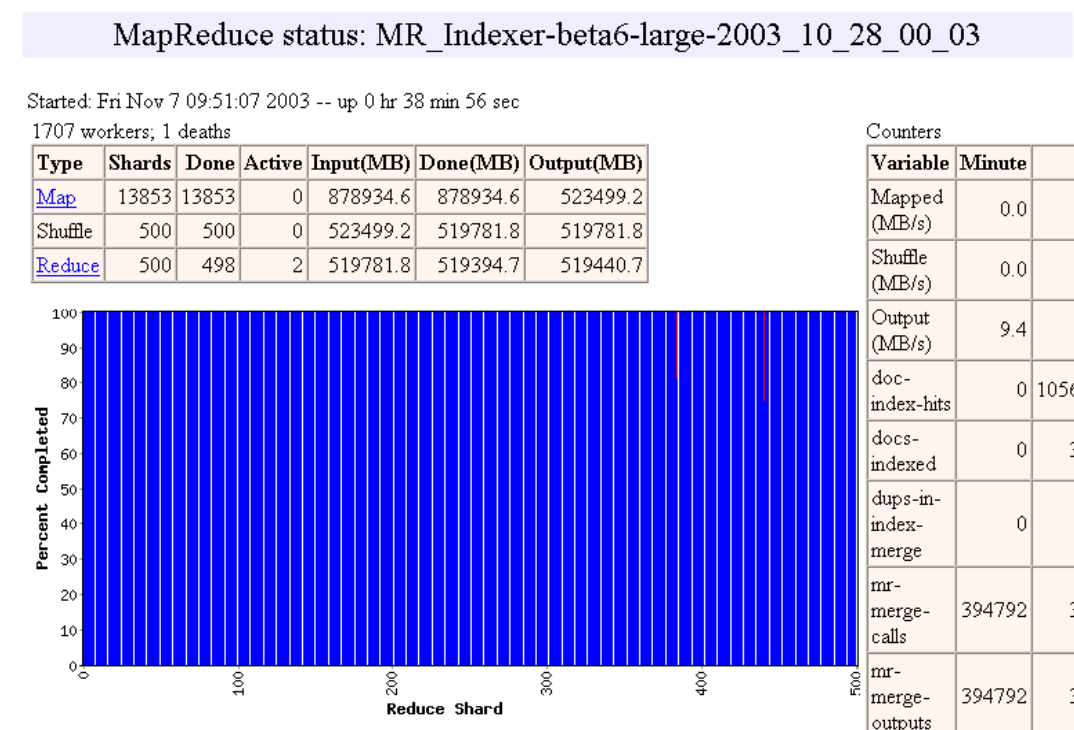
Pipelining
- Las máquinas pueden ser re-usadas para realizar tareas Map y Reduce
- A medida que las tareas Map terminan, las máquinas pueden ser utilizadas para hacer tareas Reduce
- Load Balancing dinámico
- Ejemplo de http://research.google.com/archive/mapreduce-osdi04-slides/index-auto-0010.html
Pipelining
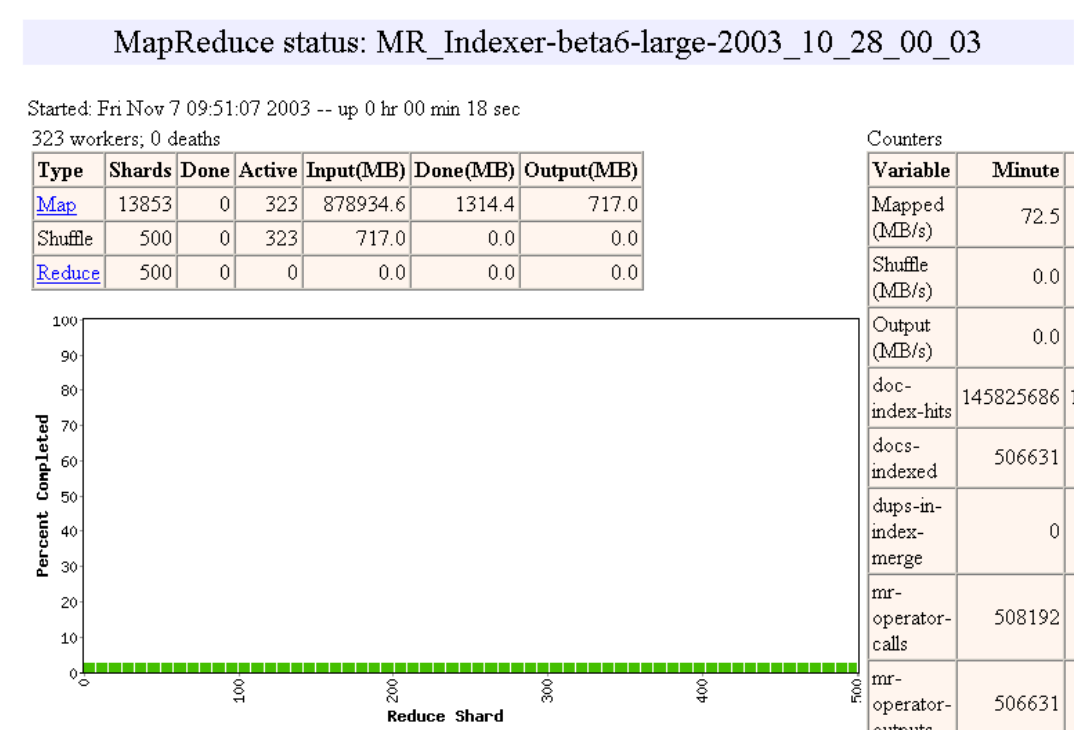
Pipelining
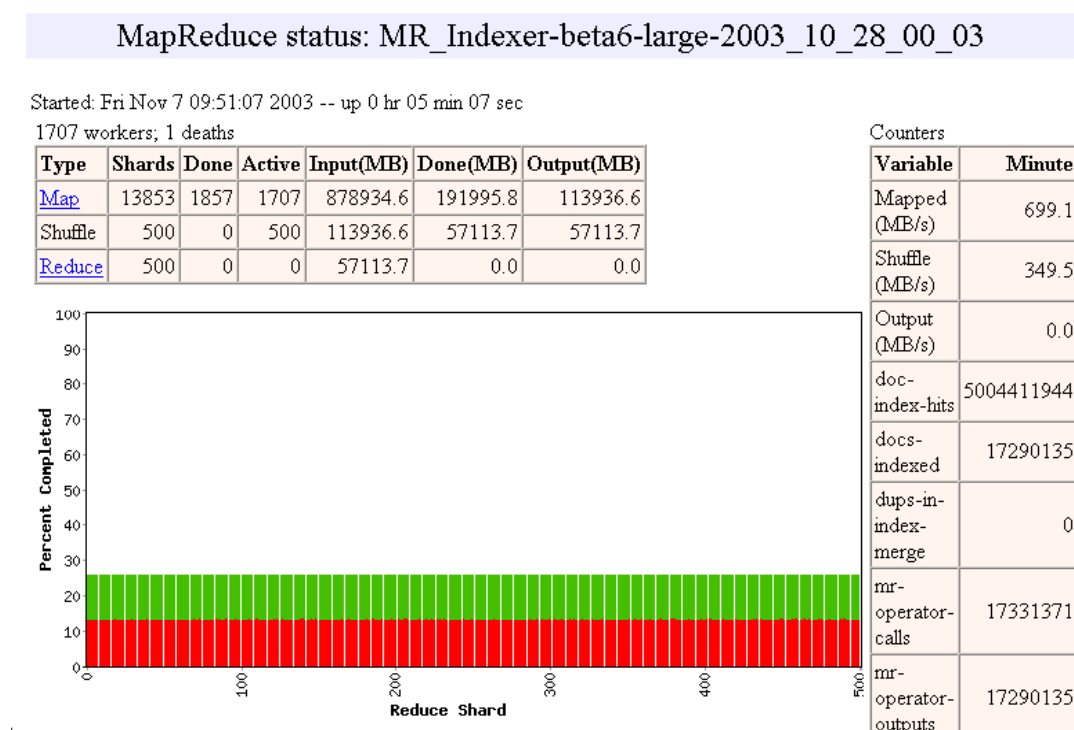
Pipelining
Pipelining
Pipelining
Pipelining
Pipelining
Pipelining
Pipelining
Pipelining
Pipelining
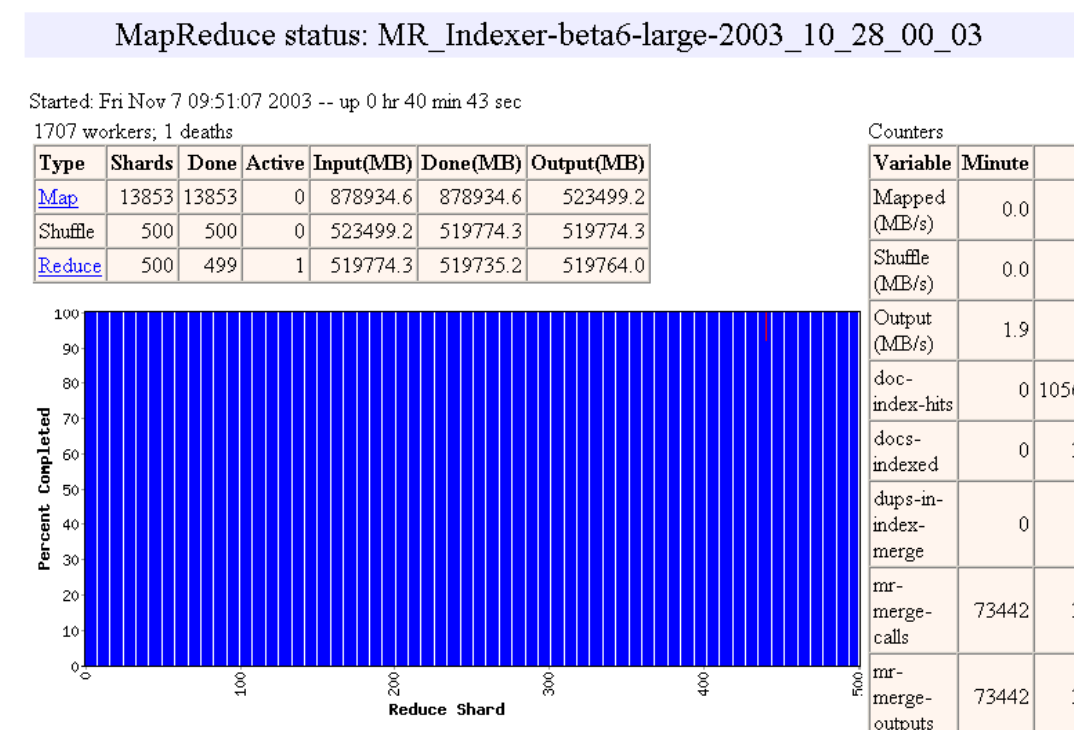
Tolerancia a Fallas
- Si el master muere, el sistema cae
-
Si un worker muere el sistema se da cuenta via heartbeats
- Re-ejecución de tareas fallidas
-
Re-ejecución de tareas en ejecución
- Mejora el peor caso (ejecución redundante)
-
Semántica en caso de fallas:
- No presenta problemas para tareas determinísticas
GFS y Localidad de los Datos
-
El GFS es un sistema de archivos distribuído
- Diseñado para trabajar bien con el modelo de cluster que hablamos antes
-
Los archivos son divididos en chunks de tamaño fijo y replicados en los nodos
- Usualmente un nivel de réplica de 3 copias por chunk
- Una buena implementación de MapReduce asigna tareas Map a nodos donde los chunks son locales
Ejemplos
- distributed grep
- distributed sort
- web link-graph reversal
- term-vector per host
- web access log stats
- inverted index construction
- document clustering
- machine learning
- statistical machine translation